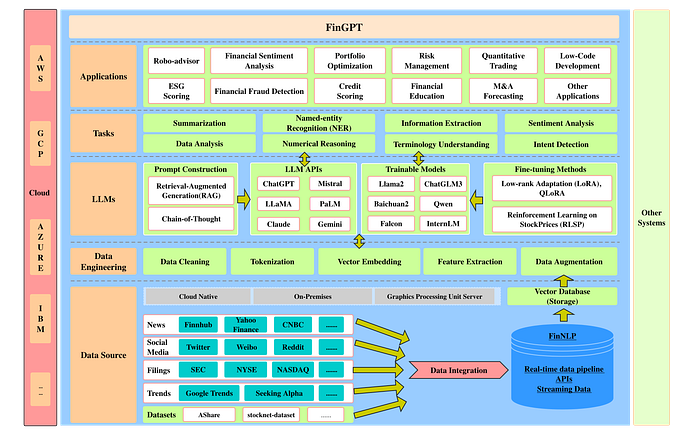
WHICH JAGUAR DID YOU MEAN?
Label unstructured data using Enterprise Knowledge Graphs 3
Target Sense Verification
This is the third part of the series about word sense disambiguation (WSD) with Knowledge Graphs (KGs).
In this part we put a special focus on disambiguation to make it even more flexible. We want to find such models that can disambiguate quickly and reliably without the need to induce at all, even if the sense inventory is incomplete, i.e. if only a single sense is known. In this article you will find a description of the method including illustrative examples, some analysis, and code samples to reproduce the results and quickly start with your own task — if you have one.
We start from a quick recap of the problem statement from Part 1.
Acknowledgement
This work is part of the Prêt-à-LLOD project with the support from the European Union’s Horizon 2020 research and innovation programme under grant agreement no. 825182.
Looking for concepts behind words
Simple examples like the one you will find below demonstrate that string matching with linguistic extensions is not enough to understand if a word represents a resource from the Knowledge Graph. We need to disambiguate words, that is to discover which concepts stand behind these words.
Given 1. a text, 2. a word of interest (or target word), 3. a Knowledge Graph — decide which resource from the Knowledge Graph does the word of interest represent. Here is an example:
BMW has designed a car that is going to drive Jaguar X1 out of the market.
This is what the typical formulation of the disambiguation against Knowledge Graph task, also called Entity Linking, would look like:
However, this formulation is only suitable for large Knowledge Graphs like DBpedia or Wikidata when one is only interested in disambiguating between the senses represented in the Knowledge Graph. For enterprise Knowledge Graphs, this task should be posted differently. Enterprise Knowledge Graphs are smaller than DBpedia and usually highly specific to their domains. Therefore, this would be a more suitable formulation of the problem statement:
Running example — “Jaguars”
[{1: “The jaguar’s present range extends from Southwestern United States and Mexico in North America, across much of Central America, and south to Paraguay and northern Argentina in South America.”},
{2: “Overall, the jaguar is the largest native cat species of the New World and the third largest in the world.”},
{3: “Given its historical distribution, the jaguar has featured prominently in the mythology of numerous indigenous American cultures, including those of the Maya and Aztec.”},
{4: “The jaguar is a compact and well-muscled animal.”},
{5: “Melanistic jaguars are informally known as black panthers, but as with all forms of polymorphism they do not form a separate species.”},
{6: “The jaguar uses scrape marks, urine, and feces to mark its territory.”},{7: “The word ‘jaguar’ is thought to derive from the Tupian word yaguara, meaning ‘beast of prey’.”},{8: “Jaguar’s business was founded as the Swallow Sidecar Company in 1922, originally making motorcycle sidecars before developing bodies for passenger cars.”},
{9: “In 1990 Ford acquired Jaguar Cars and it remained in their ownership, joined in 2000 by Land Rover, till 2008.”},
{10: “Two of the proudest moments in Jaguar’s long history in motor sport involved winning the Le Mans 24 hours race, firstly in 1951 and again in 1953.”},
{11: “He therefore accepted BMC’s offer to merge with Jaguar to form British Motor (Holdings) Limited.”},
{12: “The Jaguar E-Pace is a compact SUV, officially revealed on 13 July 2017.”}]
The example contains twelve contexts featuring the target word “jaguar” in different senses. The first six contexts speak about the “jaguar” as animal, the last five mention “jaguar” as a car manufacturer. The seventh context refers to both senses as it describes the etymology of the word. We dealt with this example in the previous part and we have shown how to induce the two desired senses. However, if we are only interested in the correct sense linking then the additional step of sense induction might be a burden and limits the range of potential applications. In this part we demonstrate how to link senses without having the whole sense inventory at hands.
Limitations of the previous approaches
In the previous parts we have seen 2 different methods that allow us to disambiguate with Enterprise Knowledge Graphs. Yet both methods require a preparatory induction step to estimate all the existing senses of the target word. As we pointed out, this is often not desirable and limits the number of use cases. For example, what if you do not have a representative corpus featuring all different senses?
Target Sense Verification
In a recent paper we introduce a new task that we call Target Sense Verification (TSV). The input is a context with the target word and sense descriptors that indicate the sense to be verified. And the task is to decide if the target word is used in that sense in the provided context. To learn more read this wonderful blogpost by Anna Breit or try out a few samples from the dataset that we have prepared.
To stress this even further, with the TSV approach we do not need to induce the senses. The model is trained on a general purpose dataset (generated from WordNet) and is readily available to disambiguate. As the challenge demonstrates, models can generalize from general purpose to domain specific settings quite well.
Code
We have published the code of the model together with a TSV dataset at a github repo. So if you have a use case and would like to try if our model would work for you — just download our repo, train the model and use it!
Here is a piece of code to get you started.
Conclusion
This was the third and last part of the series. We consider that the classifier trained on WiC-TSV dataset is the ultimate tool to disambiguate with enterprise knowledge graphs. The classifier does not require neither the complete sense inventory, nor any specific fine-tuning. It is ready to be used out of the box. Yet, if the performance is not satisfactory, it could be further trained on a small domain specific set of examples to improve its performance.
Unfortunately, the classifier is language specific. At the moment we have only published the WiC-TSV dataset in English. However, we are already working on German WiC-TSV and we have a recipe to prepare such training sets in other languages — reach out to us if this is of interest to you, we would be absolutely glad to help!